Navigating the Web with Python: Insights into Scraping and Automation Tools
- 1. Introduction
- 2. Tool overview
- 3. Choosing the right tool for the job
- 4. TLDR
- Appendix A: Exploring Additional Webpage Rendering Tools
- Appendix B: Waiting for browser rendering sucks
1. Introduction
No developer can afford not to know or interact with web technologies. From APIs to network security protocols that one needs to attend for the company, a developer, and even ‘data’ people, end up interacting with HTTP requests, VPNs, and network boundaries. But fancy jargon aside this post is not going to be either about serving on the web, developing a web application on Django or Flask, or exposing an API with FastAPI, we gonna talk about being a client, a consumer, being ‘served by the web’.
When do we act as a web client outside of traditional web browsing? This often occurs in the realms of web scraping and web automation. Web scraping involves programmatically extracting data from websites, while web automation refers to automating web-based tasks, sometimes known as Robotic Process Automation (RPA). These practices are especially relevant when dealing with legacy systems or in scenarios where direct user interaction is restricted. In this context, I want to discuss three widely used tools intended for these applications: Beautiful Soup, Selenium, and Scrapy. Each of these tools offers unique features and capabilities, making them go-to choices for web scraping and automation tasks.

2. Tool overview
2.1. Beautiful Soup
Is the simplest of the three, it is basically an HTML/XML parser that provides a more user-friendly interface for iterating, searching, and parsing the HTML document tree.

For fetching/acquiring the data to be parsed by Beautiful Soup you will need other tools such as Python’s requests built-in library to make the HTTP requests to the web services. Given its parsing nature, Beautiful Soup is a library used more for web scraping when someone wants to abstract a bit the difficulties of understanding xpaths and css selectors. A common example of using this library can be found below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import requests
from bs4 import BeautifulSoup
# URL of the webpage to scrape
url = 'https://books.toscrape.com/'
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the content of the response
soup = BeautifulSoup(response.text, 'html.parser')
# Find all h3 tags (which contain book titles)
book_titles = soup.find_all('h3')
# Extract the titles and write to a file
with open('book_titles.txt', 'w') as file:
for i, title in enumerate(book_titles):
book_title = title.find('a')['title']
line = f"{i+1}: {book_title}"
print(line)
file.write(line + '\n')
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
1: A Light in the Attic
2: Tipping the Velvet
3: Soumission
4: Sharp Objects
5: Sapiens: A Brief History of Humankind
...
2.2. Selenium
Selenium is kind of a big monster that has made a name for itself among web developers, primarily because it was originally developed for automated software testing of web applications. Its versatility is further showcased by its support for multiple programming languages, including Java, Python, C#, Ruby, JavaScript, and Kotlin. Unlike libraries that are limited to parsing HTML, Selenium offers users the ability to control a full-fledged browser, automating a wide range of tasks across several supported browsers.
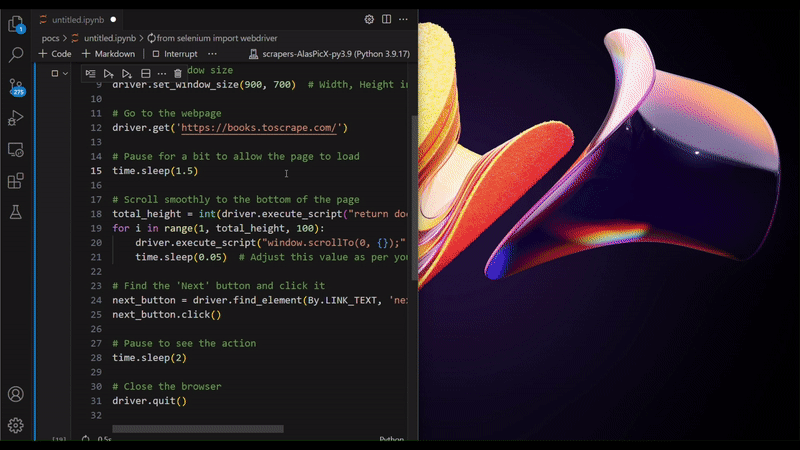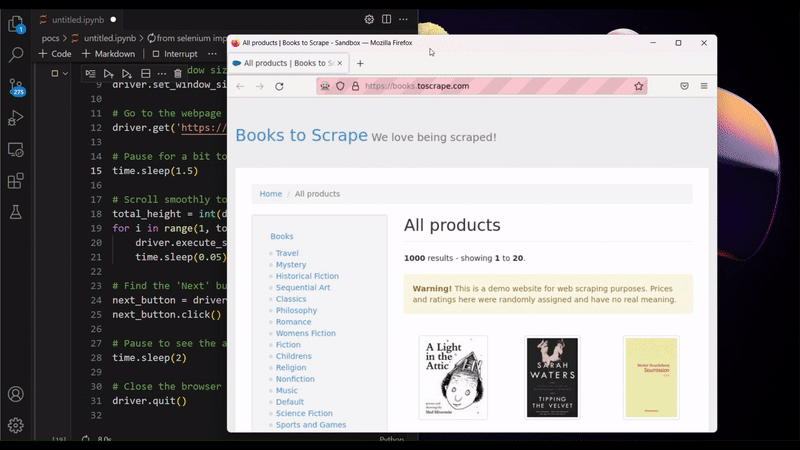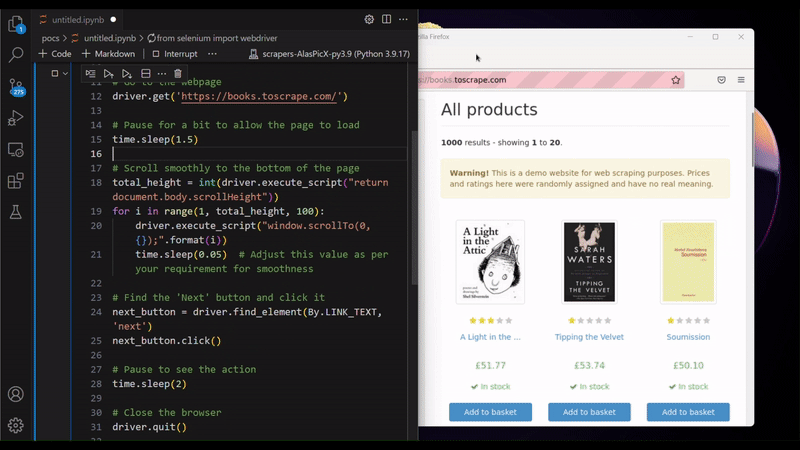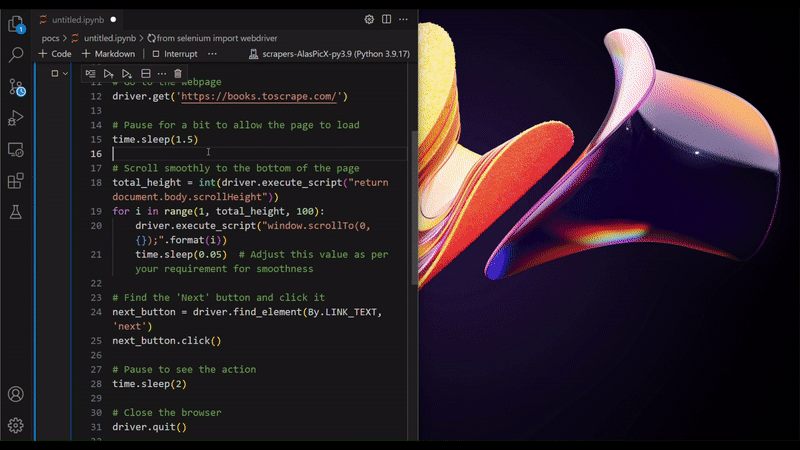
As you may have already noticed, Selenium is pretty friendly with the idea of automating web tasks, i.e. RPA, as it can click on buttons, and scroll the page, just like simulating a human interaction with the browser. But Selenium is also used for web scraping sometimes. Why is that? You may ask. Because scraping JavaScript-heavy (JS-heavy) websites is not as straightforward as doing HTTP requests. For example:
- Browse to the www.openweb.com webpage
- Open the developer tools (F12 usually);
- Disable the JavaScript. You can look for the check box or press ctrl + shift + P, then “disable javascript” on the search box;
- Update the page (F5);
You will notice that things don’t look the same. You may also make an HTTP request to this page and check the returned HTML doesn’t have all the information you can see on the HTML of your browser.
Now you see that things are not what they look like. Web pages on JS-heavy sites may appear static, but there’s more than meets the eye. Often, these pages dynamically load content, initiating new requests for assets after the initial page render. This is due to the site’s JavaScript, which fetches additional data and updates the display in real time. For those new to web development, a practical way to observe this is by opening the ‘network’ tab in your browser’s developer tools. There, you can monitor the various requests your browser makes to fully render the page.
Because of these types of sites Selenium shines in the scrappy activity, as it is a full browser, it automatically runs all the JS that is needed to render the page for you, landing the data you want to acquire directly on the modified page HTML.
Wait! For those JS-heavy sites, I can only hope to wait for a tool like Selenium to render the page?
Actually no, you can replicate the requests you found on the ‘network’ tab on your Python code, using Selenium just makes the job pretty easy, despite adding a lot of latency and asking for more computing resources.
2.3. Scrapy
Scrapy is a bit different from Beautiful Soup and Selenium. Scrapy is a framework, not a library. Instead of writing code that uses Scrapy, you write code that the Scrapy framework will use. For example, if you want to craw and dump a whole website you just need to:
- Run the scrappy create command:
scrapy startproject <project-name>; - Put a code similar to this one in the spider:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import os
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ExampleCrawlSpider(CrawlSpider):
name = 'examplecrawlspider'
allowed_domains = ['example.com'] # Replace with the target domain
start_urls = ['http://example.com'] # Replace with the starting URL
rules = (
# Rule to follow links (LinkExtractor), calling the defined
# 'parse_item' method
Rule(LinkExtractor(), callback='parse_item', follow=True),
)
def parse_item(self, response):
# Extract the entire content of the <body> tag from the response
page_content = response.css('body').get()
filename = f'dumped_pages/{response.url.split("/")[-1]}.html'
if filename == 'dumped_pages/.html':
filename = 'dumped_pages/index.html'
if not os.path.exists('dumped_pages'):
os.makedirs('dumped_pages')
with open(filename, 'wb') as f:
f.write(page_content.encode())
self.log(f'Saved file {filename}')
Note: You might need to change some configurations before running the spider
As you may imagine, by its name, Scrappy is the go-to framework for large-scale scraping and crawling. Did you start scraping with Python and now want to put things async with aiohttp? Scrapy is async by default. Need to add data validation to the extracted information? Need to do automatic throttling? Banned detection? Add/swap middleware? Distributed multi-node crawling? Scrapy can do it all.
Don’t get me wrong, I know that using a framework like Scrapy adds complexity and new things to learn, but if you think you can go a long way with Python’s request + Beautiful Soup is because you can’t see how far away you would if using Scrapy.
Note: John Watson Rooney is a pretty good channel with tutorials about Scrapy and other web scraping tools.
3. Choosing the right tool for the job
Deciding on the right tool can be overwhelming. To simplify the process, consider two main factors: the scope of your project — including the number of sites, requests, operations, or items involved — and your primary goal, which might range from web testing to simple or extensive web scraping. Wondering how to choose between the three? Below is a table that summarizes their key attributes and uses:
| Feature/Tool | Beautiful Soup | Selenium | Scrapy |
|---|---|---|---|
| Primary Use | HTML/XML Parsing | Web Automation | Large-Scale Web Scraping |
| Ease of Use | Easy for beginners | Moderate | Steeper learning curve |
| Performance | Fast for simple tasks | Slower, resource-intensive | Fast, efficient for large tasks |
| JS Heavy Sites | Limited (needs extra handling) | Excellent (renders JS) | Good (with some workarounds) |
| Scalability | Ideal for small projects | Not ideal for large-scale scraping | Highly scalable |
| Integration | Works with Python requests | Full-fledged browser control | Extensive framework capabilities |
| Best For | Quick scraping tasks, learning basics | Automating browser tasks, handling JS-heavy sites | Advanced web scraping, large-scale projects |
So, in the end, if you are looking for automation go to Selenium and if you are looking for web scraping go for Beautiful Soup or/and Scrapy (nothing prohibits you from using both).
Wait, and what about the JS-heavy sites?
Yeah, Selenium makes things easy on this front, but it’s really slow and hardware-hungry (it’s a browser in the end, everybody knows that they are becoming almost as containerized operational systems (OS)). If you need to cut costs and be blazing fast you need to go raw and do the extra request by yourself (inspect the website with the dev tools and discover what request gets the data you want) and replicate it in Beautiful Soup/Scrapy. That’s a no-brainer: when scraping, rendering is helpful for the human eye, but remember that you don’t want to render things, what you really want is the data.
4. TLDR
What to choose if I’m starting and don’t need to do a lot of requests?
- Beautiful Soup.
- But what if the site is JS-heavy?
- Selenium or Playwright.
What if I do need a lot of requests? (being I a beginner or not)
- Go for Scrapy (if you are a beginner, be brave, the effort will pay off).
If I want to automate web interactions, maybe RPA?
- Selenium/Playwright.
- You might go raw with BeatitulSoup/Scrapy, translating click and API calls, it depends on your project’s requirements. Going raw will ask you to understand the web better (API calls, headers, sessions, cookies).
Appendix A: Exploring Additional Webpage Rendering Tools
While I’ve highlighted the use of raw HTTP requests and Selenium, it’s worth noting that the ecosystem of tools for webpage rendering is rich with options. You can explore tools like Playwright, which offers browser automation capabilities such as Selenium, or Splash, a lightweight browser render service that integrates well with Scrapy. For those seeking a more managed solution, services like Zyte can render pages on your behalf.
Transitioning to raw HTTP requests can be a smooth process. Here’s an approach to deepen your web scraping techniques progressively:
- Begin with Python’s
requestslibrary in pair with Beautiful Soup. This will introduce you to the basics of web scraping and HTML parsing. - Move on to browser-based scraping with Selenium to handle JavaScript-heavy websites. You can continue to use Beautiful Soup to parse the HTML content fetched.
- Integrate Splash with Scrapy if you’re working within the Scrapy framework and need to render JavaScript without a full-fledged browser.
- Consider using Zyte’s rendering service for a server-side solution that can scale and handle complex scraping tasks without the need to manage browsers or proxies yourself.
- When ready, make the leap to Scrapy for an all-in-one framework experience, providing you with asynchronous processing capabilities and a wide range of built-in features for large-scale web scraping projects.
By pacing your learning this way, you’ll build a solid foundation in web scraping and automation, allowing you to choose the right tool for each job with more confidence.
Appendix B: Waiting for browser rendering sucks
Browser rendering delays are a common pain point in web scraping, particularly on JavaScript-rich sites. Playwright claims to handle these delays more adeptly than Selenium, though I’ve yet to thoroughly test this myself. From experience, Selenium’s built-in wait functions often fall short on such sites. I once had to engineer custom wait functions to deal with a particularly tricky site, which required me to measured max image dissimilarity between sequential screenshots to determine when the page had fully loaded.